Artificial intelligence has come a long way from simple pattern recognition to systems that can understand context, retrieve relevant information, and generate human-like responses. Among the most significant advancements in this evolution is the development of Retrieval-Augmented Generation, commonly known as RAG. This approach has become a cornerstone in building more accurate, up-to-date, and context-aware AI applications, especially in domains like customer support, research assistance, and enterprise knowledge management.
But as the demand for smarter, more autonomous AI grows, so does the complexity of retrieval systems. This has led to the emergence of two advanced variants: Agentic RAG and Graph RAG. While all three—RAG, Agentic RAG, and Graph RAG—share the core idea of combining retrieval with generation, they differ significantly in architecture, capabilities, and use cases.
This article breaks down each concept in detail, explains how they work, and highlights their unique strengths. Whether you’re a developer, a data scientist, or simply curious about the future of AI, understanding these systems will give you a clearer picture of where intelligent information processing is headed.
What Is RAG? The Foundation of Modern AI Retrieval
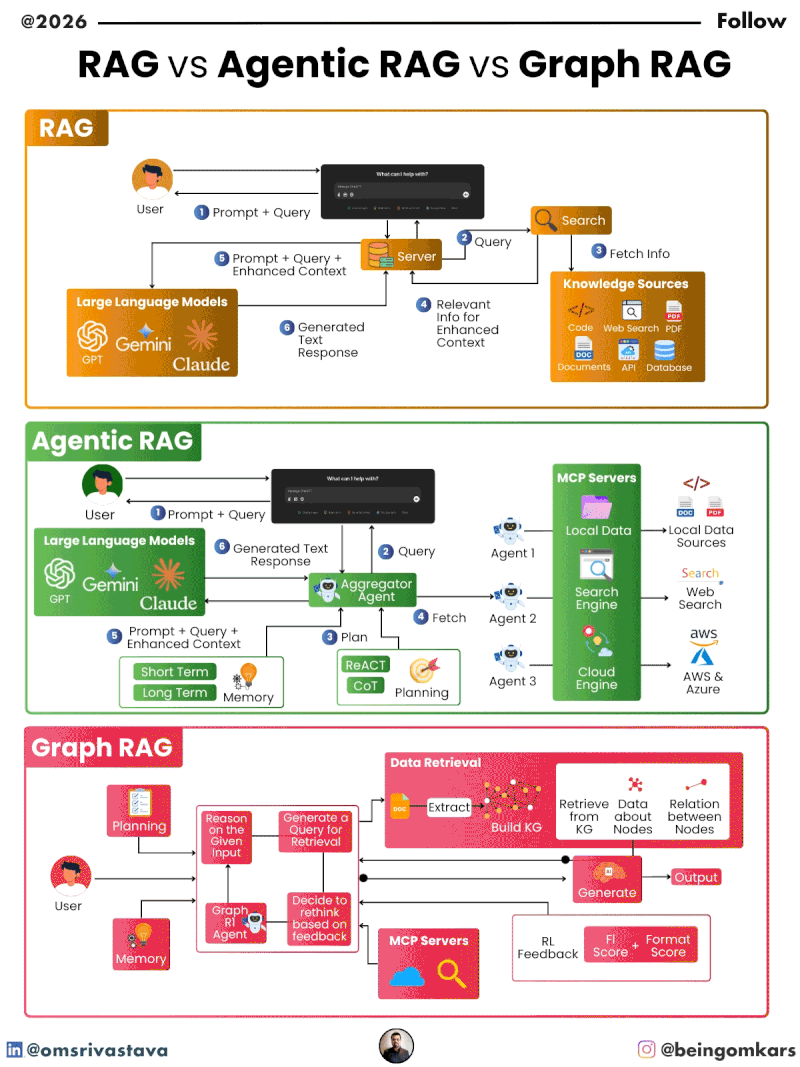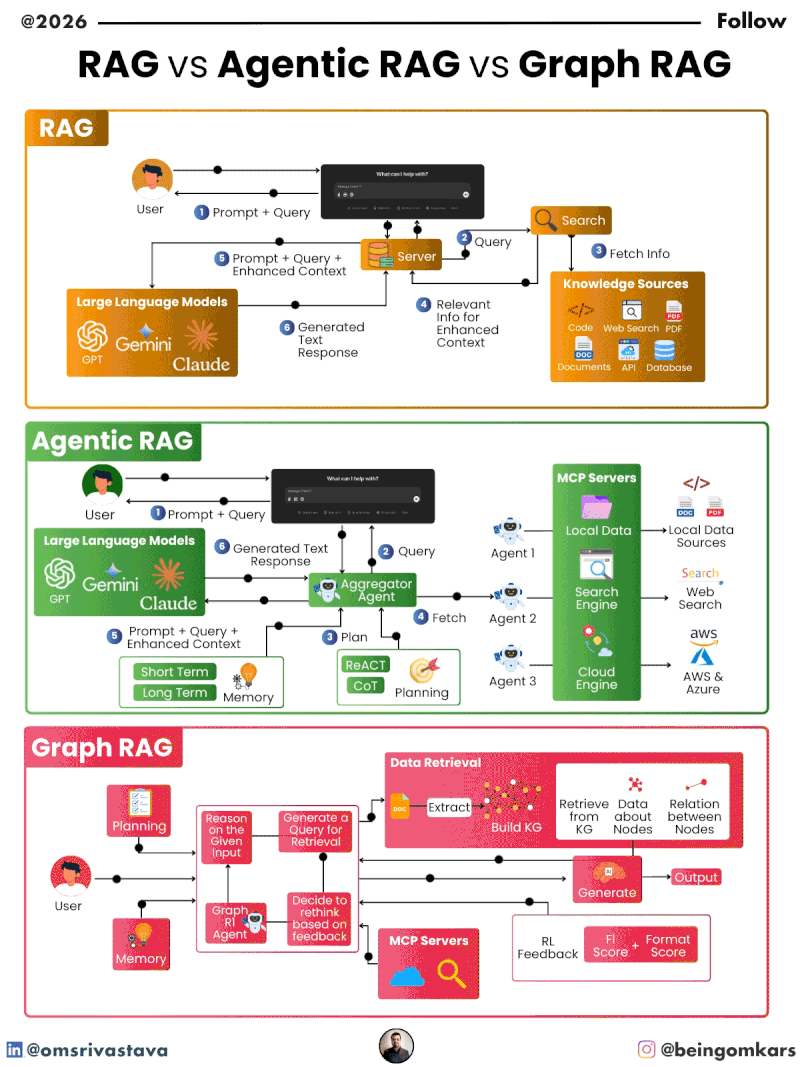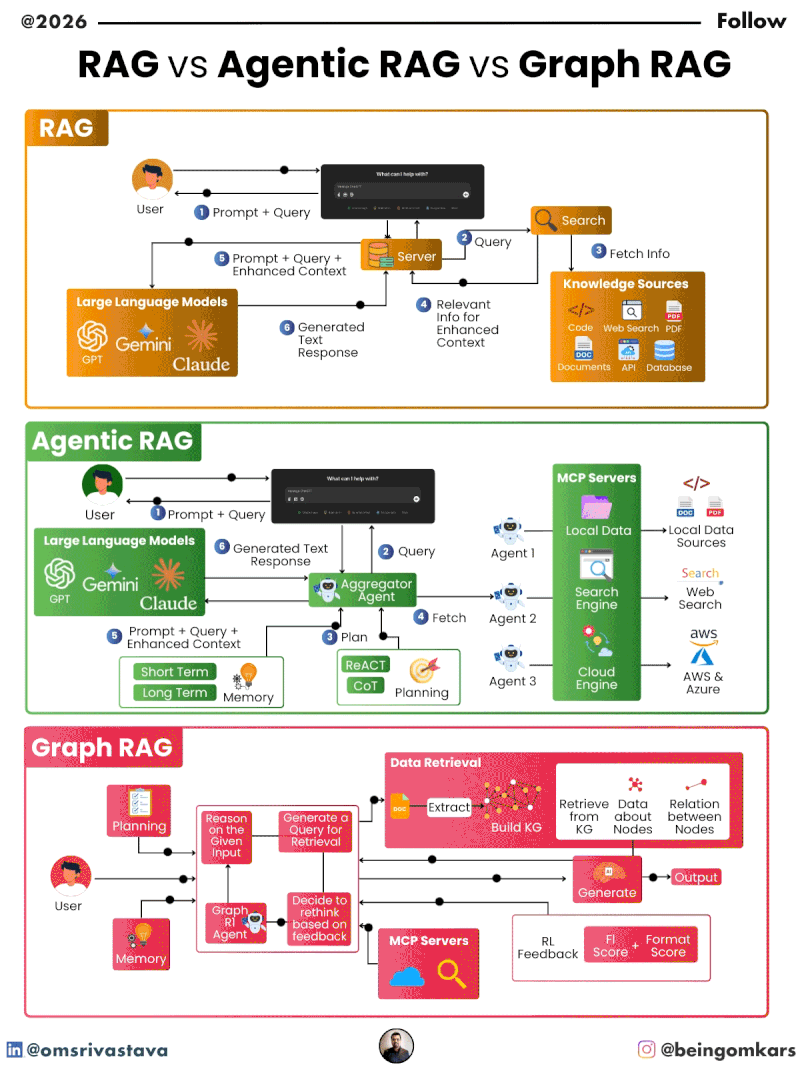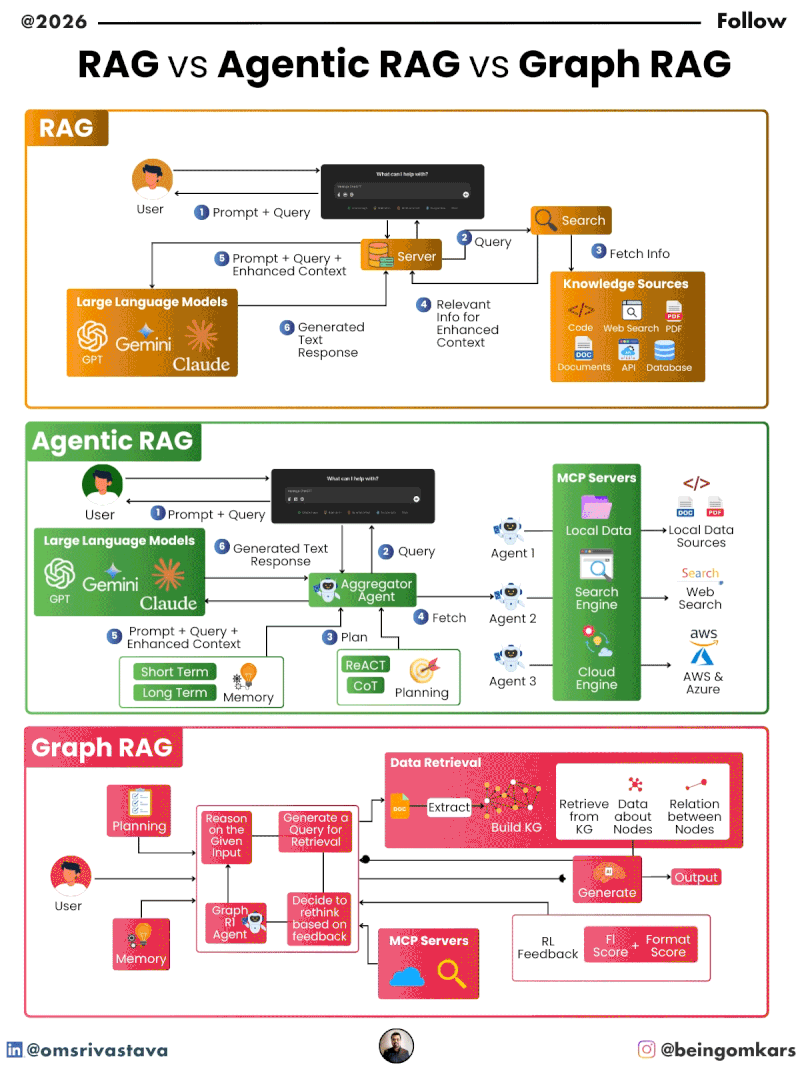
Retrieval-Augmented Generation (RAG) is a hybrid AI architecture that enhances large language models (LLMs) by integrating external knowledge retrieval into the response generation process. Instead of relying solely on the static knowledge embedded during training, RAG systems dynamically fetch relevant information from a database or document store before generating a response.
The core idea behind RAG is simple: when a user asks a question, the system first searches a knowledge base for documents or passages that might contain the answer. These retrieved snippets are then fed into the language model along with the original query. The model uses this additional context to produce a more accurate, factual, and relevant response.
How RAG Works: A Step-by-Step Breakdown
The RAG process typically involves three main stages:
- Retrieval: When a query is received, the system converts it into a numerical vector (embedding) using an embedding model. This vector is then compared against a pre-built index of document embeddings to find the most similar passages. Common retrieval methods include dense vector search using models like Sentence-BERT or DPR (Dense Passage Retriever).
- Augmentation: The top-k retrieved documents are concatenated with the original query to form a richer input prompt. This augmented prompt provides the language model with external context that was not part of its training data.
- Generation: The language model processes the augmented prompt and generates a coherent, contextually appropriate response. Because the model has access to up-to-date or domain-specific information, the output is often more accurate and less prone to hallucination.
One of the key advantages of RAG is its ability to stay current. Since the retrieval component pulls from an external database, the system can incorporate new information without retraining the entire model. This makes RAG particularly useful in fields where knowledge evolves rapidly, such as medicine, law, or technology.
Use Cases and Limitations of Traditional RAG
RAG has been widely adopted in applications like chatbots, virtual assistants, and enterprise search engines. For example, a company might use RAG to build a support bot that answers employee questions by retrieving information from internal wikis, policy documents, or FAQs.
However, traditional RAG has its limitations. The retrieval step often relies on keyword or semantic similarity, which can miss nuanced relationships between concepts. It also assumes that the most relevant documents are sufficient to answer the query—something that isn’t always true. In complex scenarios, a single document may not contain the full answer, or the retrieved information might be outdated or incomplete.
Moreover, RAG systems typically follow a fixed pipeline: retrieve, then generate. They don’t adapt their behavior based on the results of retrieval or the quality of the generated response. This lack of feedback loops can lead to suboptimal performance, especially when the initial retrieval fails to capture the right context.
Agentic RAG: Adding Autonomy and Decision-Making
As AI systems are expected to handle more complex tasks, the need for greater autonomy has led to the development of Agentic RAG. Unlike traditional RAG, which follows a rigid retrieval-then-generate workflow, Agentic RAG introduces intelligent agents that can make decisions, plan actions, and iterate based on feedback.
The term “agentic” refers to the system’s ability to act independently, assess outcomes, and adjust its strategy. In the context of RAG, this means the system doesn’t just retrieve once and generate—it can evaluate whether the retrieved information is sufficient, decide to search again, refine the query, or even break down a complex question into smaller sub-questions.
How Agentic RAG Enhances the RAG Framework
Agentic RAG builds on the foundation of traditional RAG but adds layers of reasoning and control. At its core is an AI agent—often implemented using reinforcement learning, planning algorithms, or rule-based logic—that manages the retrieval and generation process.
For example, when faced with a complex query like “What were the economic impacts of the 2008 financial crisis on European small businesses?”, a traditional RAG system might retrieve a few general documents about the crisis and generate a broad answer. An Agentic RAG system, on the other hand, might:
- Break the question into sub-questions: “What was the 2008 financial crisis?”, “How did it affect Europe?”, “What defines a small business in this context?”, “What economic indicators changed?”
- Retrieve relevant documents for each sub-question
- Synthesize the information into a coherent response
- Evaluate the completeness of the answer and decide whether additional retrieval is needed
This iterative, goal-driven approach allows Agentic RAG to handle multi-step reasoning and adapt to uncertainty. It can also incorporate user feedback—such as “That’s not what I meant”—to refine its search strategy in real time.
Key Components of Agentic RAG
Several components enable the agentic behavior in these systems:
- Planner: Determines the sequence of actions needed to answer a query. This could involve decomposing the question, selecting retrieval strategies, or deciding when to stop.
- Memory: Stores intermediate results, past queries, and user interactions to inform future decisions.
- Evaluator: Assesses the quality of retrieved information and generated responses, often using heuristics, confidence scores, or external validation.
- Tool Use: Allows the agent to interact with external tools, such as web search APIs, databases, or calculators, to gather additional data.
These components work together to create a more dynamic and responsive system. For instance, if the evaluator detects that the retrieved documents are too general, the planner might instruct the system to refine the search query or switch to a different data source.
Applications and Challenges
Agentic RAG is particularly useful in domains requiring deep reasoning, such as legal research, scientific inquiry, or strategic planning. It can assist researchers by automatically gathering and synthesizing information from multiple sources, or help analysts explore complex datasets through natural language queries.
However, building effective Agentic RAG systems is challenging. They require careful design of the agent’s decision-making logic, robust evaluation mechanisms, and often significant computational resources. There’s also the risk of over-automation—where the agent makes incorrect assumptions or pursues irrelevant paths—leading to poor outcomes.
Despite these challenges, Agentic RAG represents a significant step toward more intelligent and autonomous AI systems. By moving beyond passive retrieval, it enables AI to act more like a human expert—questioning, exploring, and refining its understanding over time.
Graph RAG: Leveraging Relationships for Smarter Retrieval
While traditional and Agentic RAG rely primarily on textual similarity, Graph RAG introduces a new dimension: structure. Instead of treating documents as isolated chunks of text, Graph RAG organizes information as a graph—where nodes represent entities (like people, places, or concepts) and edges represent relationships between them.
This approach is inspired by knowledge graphs, which have long been used in semantic search and AI reasoning. By modeling information as a graph, Graph RAG can capture complex relationships, infer missing connections, and retrieve information based on contextual relevance rather than just keyword matching.
How Graph RAG Works
In a Graph RAG system, the knowledge base is structured as a graph database. Each document or piece of information is parsed to extract entities and their relationships, which are then stored as nodes and edges. For example, a document about climate change might generate nodes for “carbon emissions,” “global warming,” and “renewable energy,” with edges indicating causal or correlational relationships.
When a query is received, the system doesn’t just search for similar text—it traverses the graph to find relevant paths. For instance, a query like “How does deforestation affect biodiversity?” might trigger a search for nodes related to “deforestation” and “biodiversity,” then follow edges to discover intermediate concepts like “habitat loss” or “species extinction.”
This graph-based retrieval allows the system to uncover indirect connections that might be missed in a flat document index. It also enables more precise answers by grounding responses in a network of verified relationships.
Advantages Over Traditional RAG
Graph RAG offers several advantages:
- Contextual Understanding: By modeling relationships, the system can better understand the context of a query. For example, it can distinguish between “Apple the company” and “apple the fruit” based on surrounding nodes.
- Multi-Hop Reasoning: The system can answer questions that require connecting multiple pieces of information. For example, “Who was the mentor of the scientist who discovered penicillin?” involves traversing several relationship steps.
- Dynamic Updates: Adding new information to a graph is often easier than updating a vector index. New nodes and edges can be inserted without reprocessing the entire dataset.
- Explainability: Because the retrieval path is explicit, it’s easier to trace how the system arrived at an answer—a key requirement in high-stakes applications like healthcare or finance.
Building a Graph RAG System
Constructing a Graph RAG system involves several steps:
- Entity and Relation Extraction: Using NLP techniques to identify entities and relationships in text. Tools like spaCy, Stanford NLP, or transformer-based models (e.g., BERT) can be used for this purpose.
- Graph Construction: Storing the extracted data in a graph database such as Neo4j, Amazon Neptune, or a custom solution.
- Query Processing: Converting natural language queries into graph traversal operations. This may involve query rewriting, entity linking, and pathfinding algorithms.
- Integration with LLM: Feeding the retrieved graph paths or subgraphs into the language model to generate a response.
One challenge is ensuring the graph remains accurate and up-to-date. Incorrect relationships or missing nodes can lead to flawed reasoning. Therefore, ongoing maintenance and validation are essential.
Real-World Applications
Graph RAG is particularly effective in domains with rich relational data, such as:
- Healthcare: Linking symptoms, diseases, treatments, and patient histories to support clinical decision-making.
- Finance: Mapping transactions, entities, and regulatory relationships to detect fraud or assess risk.
- Scientific Research: Connecting papers, authors, institutions, and findings to accelerate discovery.
- Enterprise Knowledge Management: Organizing internal documents, policies, and expertise into a navigable knowledge network.
For example, a pharmaceutical company might use Graph RAG to help researchers explore drug interactions by traversing a graph of compounds, biological targets, and clinical trial results.
Comparing RAG, Agentic RAG, and Graph RAG
While all three approaches aim to improve AI-generated responses by incorporating external knowledge, they differ in complexity, capabilities, and ideal use cases.
| Feature | RAG | Agentic RAG | Graph RAG |
|---|---|---|---|
| Core Mechanism | Retrieve documents → Generate response | Plan → Retrieve → Evaluate → Iterate | Traverse knowledge graph → Generate response |
| Autonomy | Low (fixed pipeline) | High (adaptive, decision-making) | Medium (structured retrieval) |
| Reasoning Ability | Basic (single-step) | Advanced (multi-step, iterative) | Moderate (relationship-based) |
| Data Structure | Flat document index | Document index + agent memory | Knowledge graph |
| Best For | Simple Q&A, FAQ bots | Complex reasoning, research | Relational queries, domain expertise |
Traditional RAG is the most straightforward and widely used, ideal for applications where speed and simplicity are priorities. Agentic RAG excels in scenarios requiring exploration, adaptation, and multi-step logic. Graph RAG shines when the underlying data has rich interconnections and the answers depend on understanding relationships.
Key Takeaways
- RAG combines retrieval from external sources with language model generation to produce more accurate and up-to-date responses. It’s effective for straightforward information retrieval but lacks adaptability.
- Agentic RAG enhances RAG by introducing autonomous agents that can plan, evaluate, and iterate. It supports complex reasoning and dynamic decision-making, making it suitable for advanced applications.
- Graph RAG leverages structured knowledge graphs to capture relationships between entities. It enables contextual understanding and multi-hop reasoning, ideal for domains with interconnected data.
- Each approach has trade-offs in terms of complexity, performance, and maintenance. The choice depends on the specific use case, data structure, and desired level of intelligence.
- As AI continues to evolve, hybrid systems that combine elements of all three—such as agentic graph-based retrieval—are likely to become more common.
FAQ
What is the main difference between RAG and traditional language models?
Traditional language models generate responses based solely on their training data, which can become outdated. RAG enhances this by retrieving current, relevant information from external sources before generating a response, leading to more accurate and factual outputs.
Can Agentic RAG work without a knowledge graph?
Yes. Agentic RAG focuses on autonomous decision-making and iterative retrieval, which can be applied to any retrieval system—including traditional document-based RAG. However, combining it with Graph RAG can further enhance reasoning capabilities.
Is Graph RAG harder to implement than regular RAG?
Generally, yes. Graph RAG requires building and maintaining a knowledge graph, which involves entity extraction, relationship modeling, and graph database management. This adds complexity compared to simple document indexing, but the payoff is greater contextual understanding and reasoning power.