Imagine teaching a child to recognize different types of fruit. You show them apples, bananas, and oranges, pointing out features like color, shape, and texture. Over time, the child learns to identify each fruit even when it’s slightly different from the examples they’ve seen. A machine learning model works in a similar way—except instead of a child, it’s a computer program that learns patterns from data to make predictions or decisions.
In simple terms, a machine learning model is a mathematical representation of a real-world process. It’s built using algorithms that analyze large amounts of data, identify patterns, and use those patterns to make predictions on new, unseen data. These models are at the core of technologies like recommendation systems, voice assistants, fraud detection, and self-driving cars.
How Do Machine Learning Models Learn?
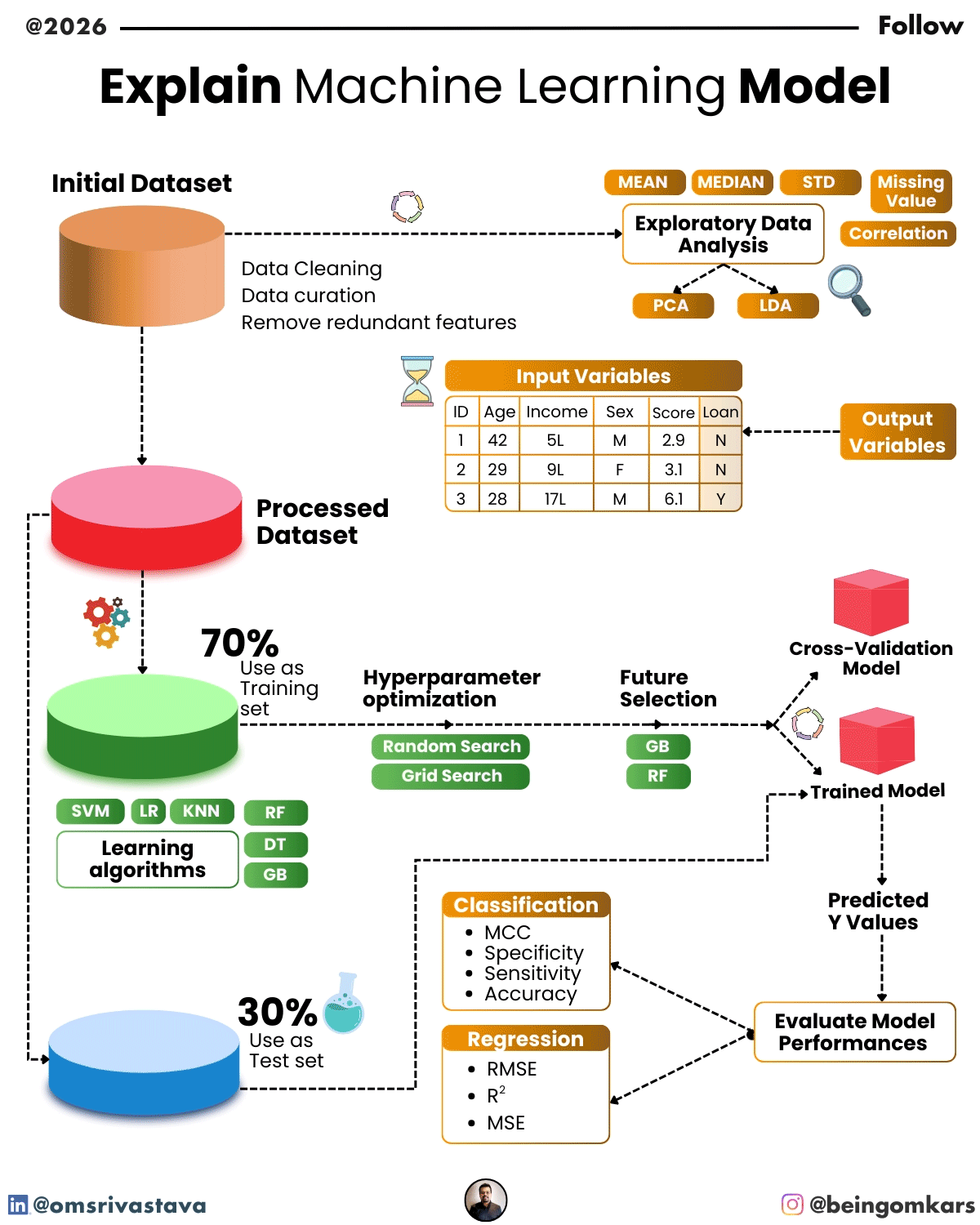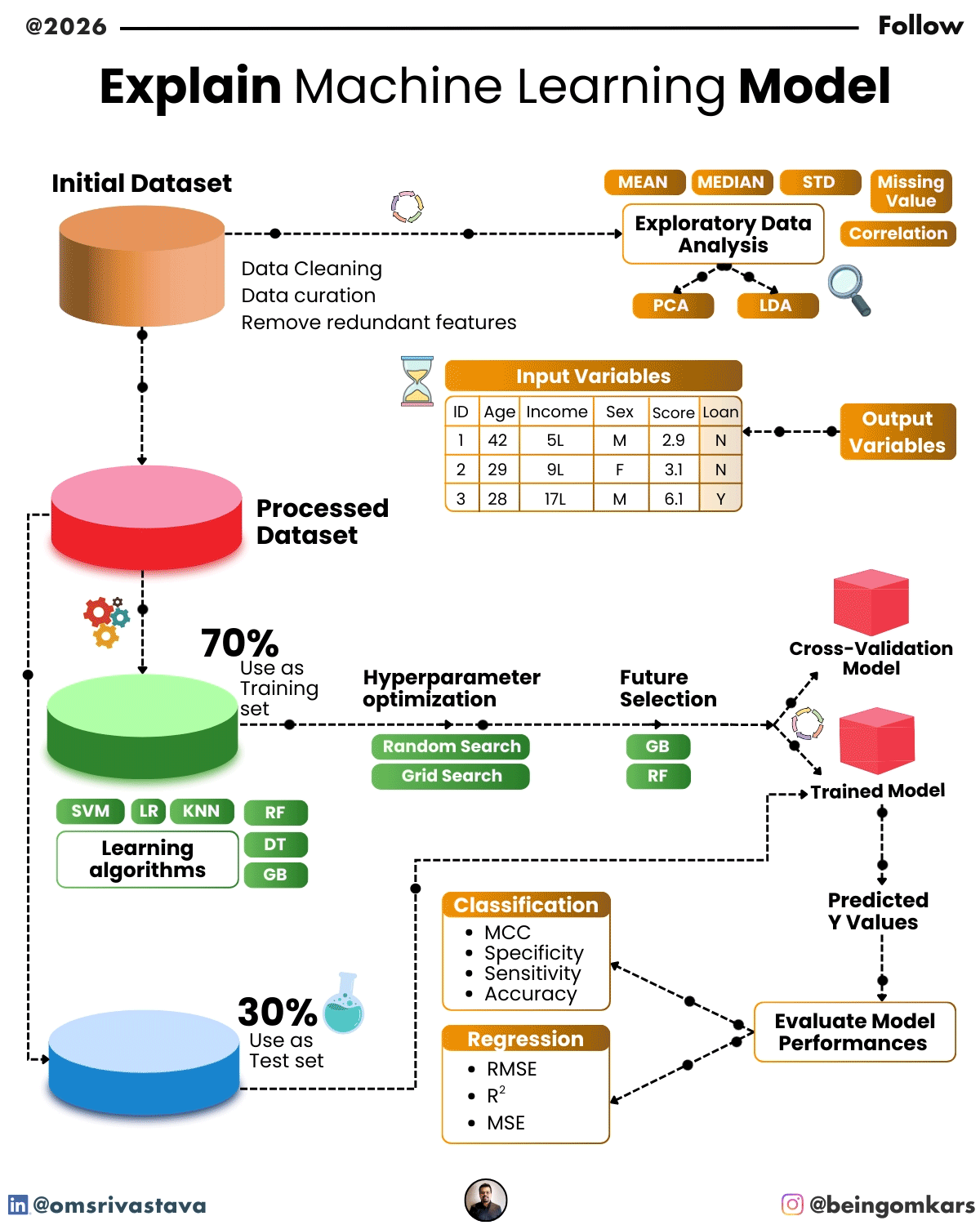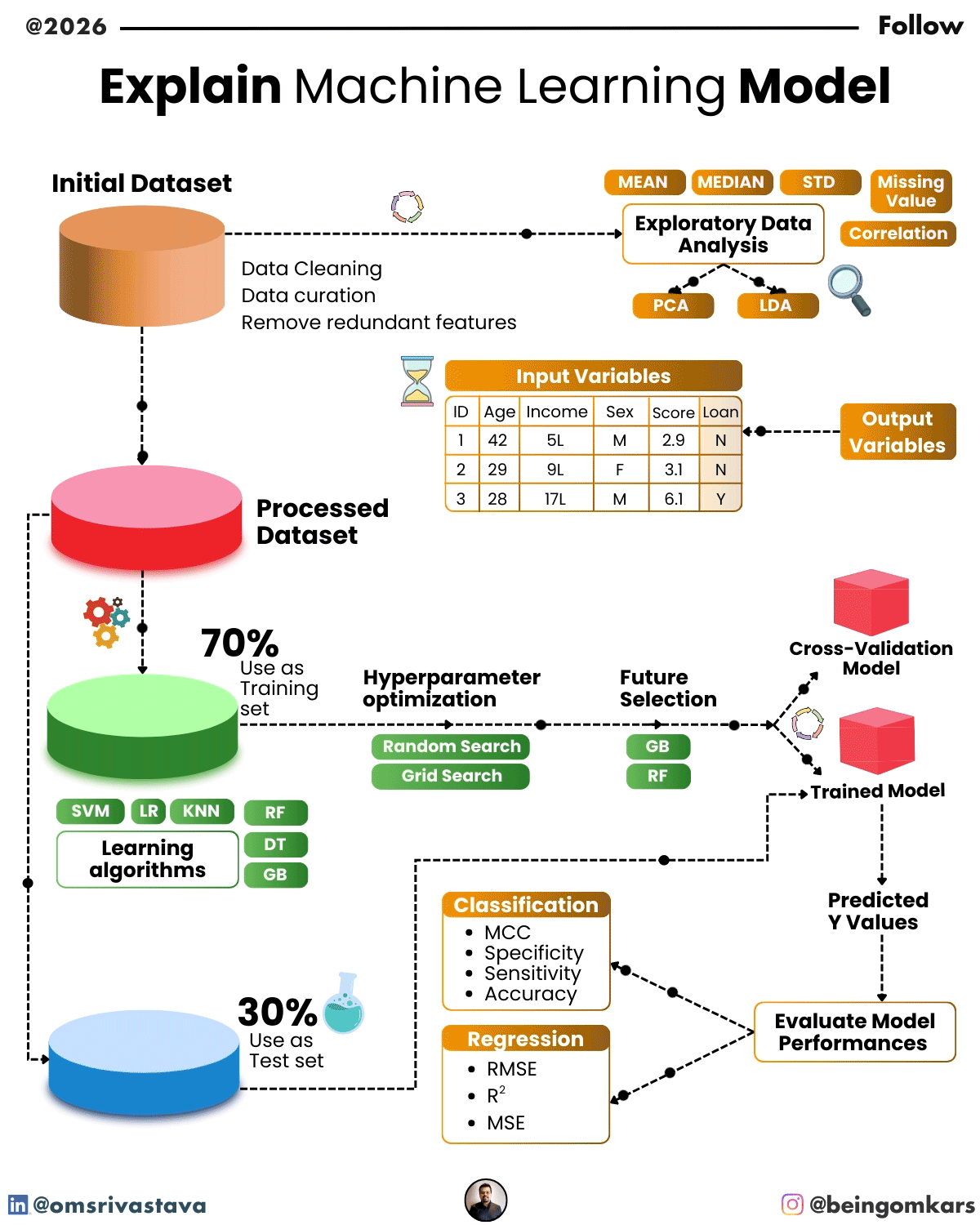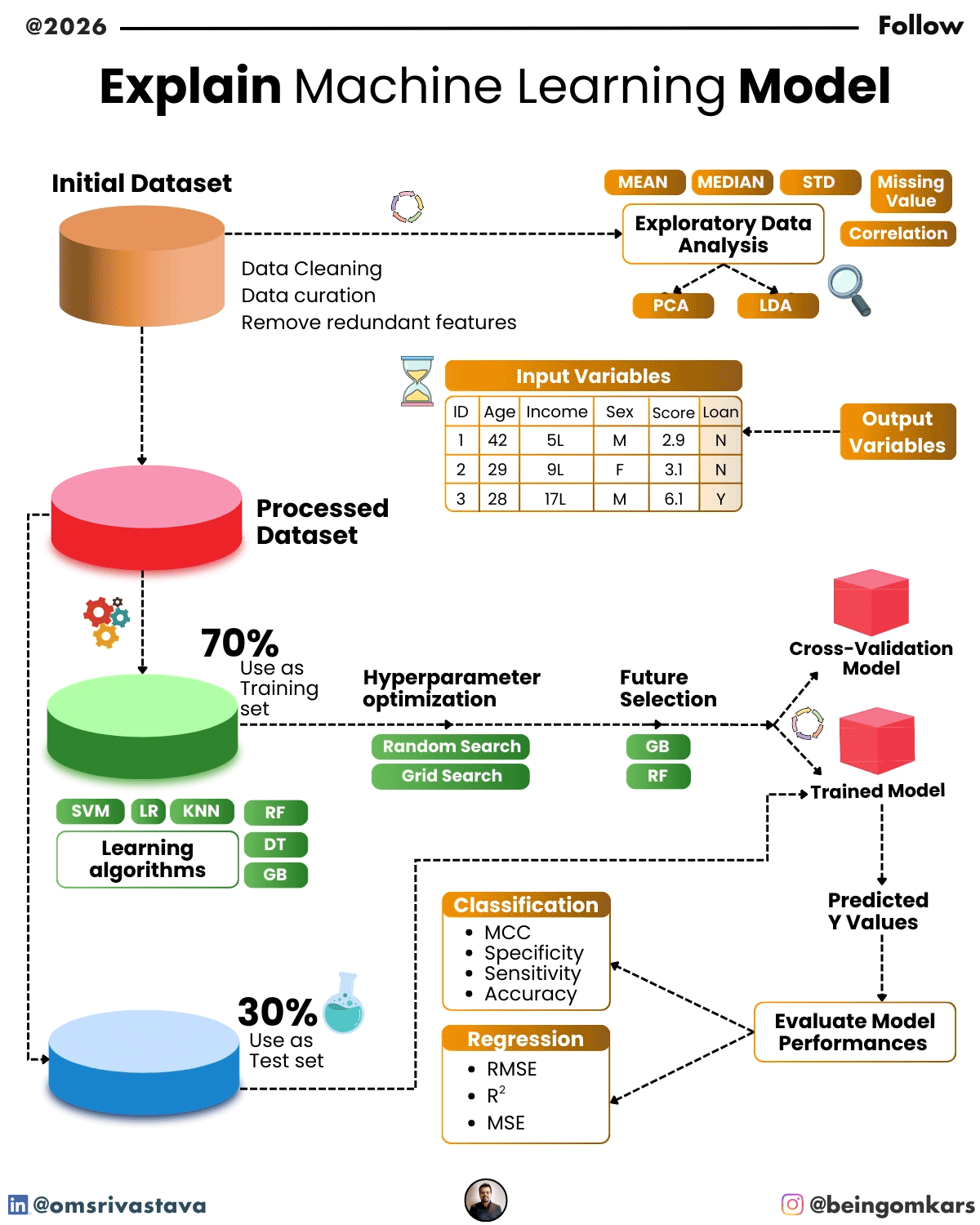
Learning in machine learning happens through a process called training. During training, the model is fed a dataset—a collection of examples with known outcomes. For instance, if the goal is to predict whether an email is spam, the training data would include thousands of emails labeled as “spam” or “not spam.”
The model examines these examples, adjusts its internal parameters, and gradually improves its ability to classify new emails correctly. This process is guided by a loss function, which measures how far off the model’s predictions are from the actual results. The model then uses optimization techniques—like gradient descent—to minimize this error and improve accuracy.
Once training is complete, the model is tested on a separate dataset to evaluate its performance. If it performs well, it can be deployed to make real-world predictions.
Types of Machine Learning Models
Machine learning models are generally categorized into three main types based on how they learn: supervised, unsupervised, and reinforcement learning.
Supervised Learning Models
In supervised learning, the model is trained on labeled data—meaning each input comes with a known output. The goal is to learn a mapping from inputs to outputs so the model can predict the correct label for new data.
- Classification models predict discrete categories. Examples include identifying whether an image contains a cat or a dog, or determining if a loan applicant is high-risk.
- Regression models predict continuous numerical values. For example, forecasting house prices based on features like size, location, and number of rooms.
Common algorithms in this category include linear regression, logistic regression, decision trees, and support vector machines.
Unsupervised Learning Models
Unsupervised learning deals with unlabeled data. The model’s task is to find hidden patterns or structures within the data without any guidance on what the correct output should be.
- Clustering models group similar data points together. For instance, segmenting customers based on purchasing behavior.
- Dimensionality reduction models simplify data by reducing the number of variables while preserving important information. Techniques like Principal Component Analysis (PCA) are often used for this purpose.
These models are useful when the underlying structure of the data is unknown or when preparing data for further analysis.
Reinforcement Learning Models
Reinforcement learning is inspired by behavioral psychology. Here, an agent learns to make decisions by interacting with an environment. The agent receives rewards for good actions and penalties for bad ones, gradually learning the best strategy to maximize cumulative reward.
This type of model is commonly used in robotics, game playing (like AlphaGo), and autonomous systems. Unlike supervised learning, there’s no labeled dataset—learning happens through trial and error.
Key Components of a Machine Learning Model
Every machine learning model consists of several core components that work together to enable learning and prediction.
- Features: These are the input variables used to make predictions. In a model predicting house prices, features might include square footage, number of bedrooms, and neighborhood.
- Algorithm: The mathematical method used to learn from the data. Different algorithms are suited to different types of problems.
- Parameters: Internal variables that the model adjusts during training to improve performance. For example, the weights in a neural network.
- Hyperparameters: Settings that are set before training begins, such as learning rate or the number of layers in a neural network. These are often tuned to optimize model performance.
The effectiveness of a model depends not only on the algorithm but also on the quality and relevance of the data, the choice of features, and how well the hyperparameters are configured.
Challenges in Building Machine Learning Models
Despite their power, machine learning models come with challenges. One major issue is overfitting, where a model learns the training data too well, including noise and irrelevant details, leading to poor performance on new data. Techniques like cross-validation and regularization help mitigate this.
Another challenge is bias in data. If the training data is not representative of real-world conditions, the model may produce unfair or inaccurate results. For example, a facial recognition system trained mostly on one demographic may perform poorly on others.
Additionally, some models—especially deep learning models—are often described as “black boxes” because their decision-making process is not easily interpretable. This lack of transparency can be problematic in high-stakes applications like healthcare or criminal justice.
Key Takeaways
- A machine learning model is a program that learns patterns from data to make predictions or decisions.
- Models are trained using data and improve through feedback, guided by algorithms and optimization techniques.
- The three main types are supervised, unsupervised, and reinforcement learning, each suited to different kinds of problems.
- Important components include features, algorithms, parameters, and hyperparameters.
- Challenges such as overfitting, data bias, and lack of interpretability must be carefully managed.
Frequently Asked Questions
What is the difference between a machine learning model and an algorithm?
An algorithm is the method or procedure used to learn from data, while a model is the result of applying that algorithm to a dataset. Think of the algorithm as the recipe and the model as the cake you bake using that recipe.
Can a machine learning model work without data?
No. Data is essential for training a machine learning model. Without data, there’s nothing for the model to learn from. The quality, quantity, and relevance of the data directly affect the model’s performance.
How do you know if a machine learning model is good?
A model’s performance is evaluated using metrics like accuracy, precision, recall, or mean squared error, depending on the task. It’s also important to test the model on unseen data to ensure it generalizes well beyond the training set.