Everyone is suddenly an AI expert. Drop into any tech conversation right now and you’ll hear these four terms used interchangeably, weaponized to sound sophisticated, or deployed so loosely that they stop meaning anything. That’s a problem — not because terminology is sacred, but because these are genuinely different things, and confusing them leads to bad decisions about what to build, what to buy, and what to expect.
So let’s untangle them. Not with a glossary, but with enough context to actually be useful.
Start Here: The Layer Cake
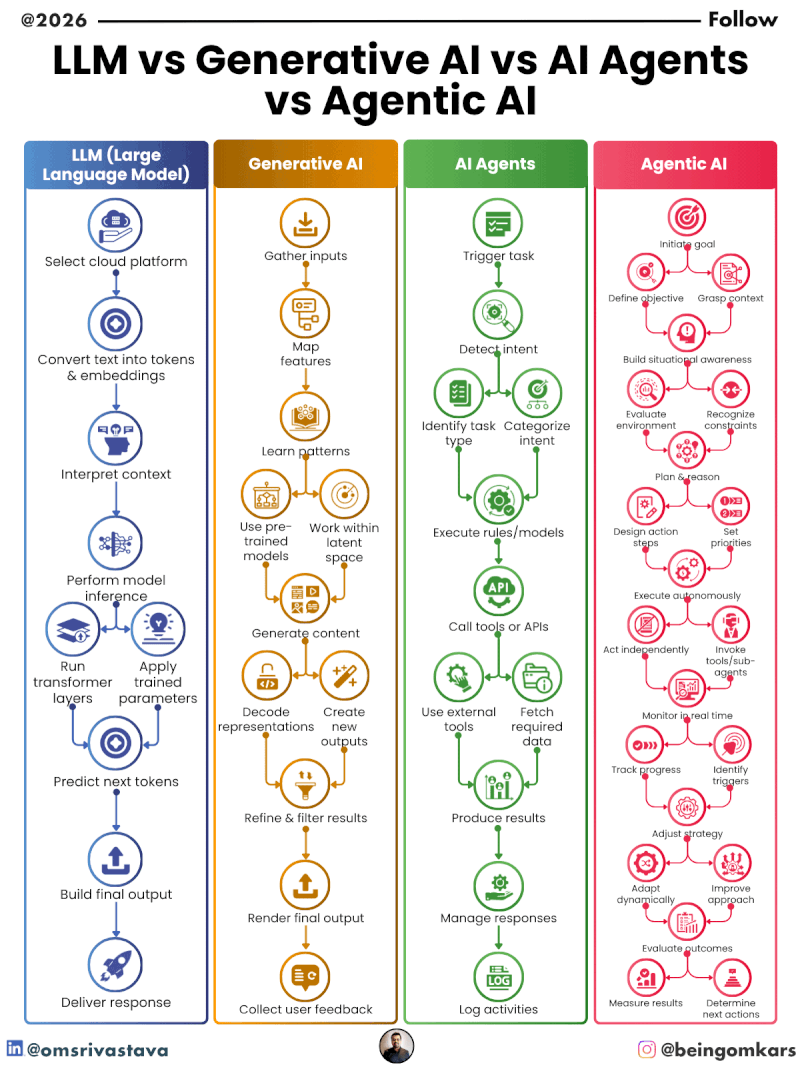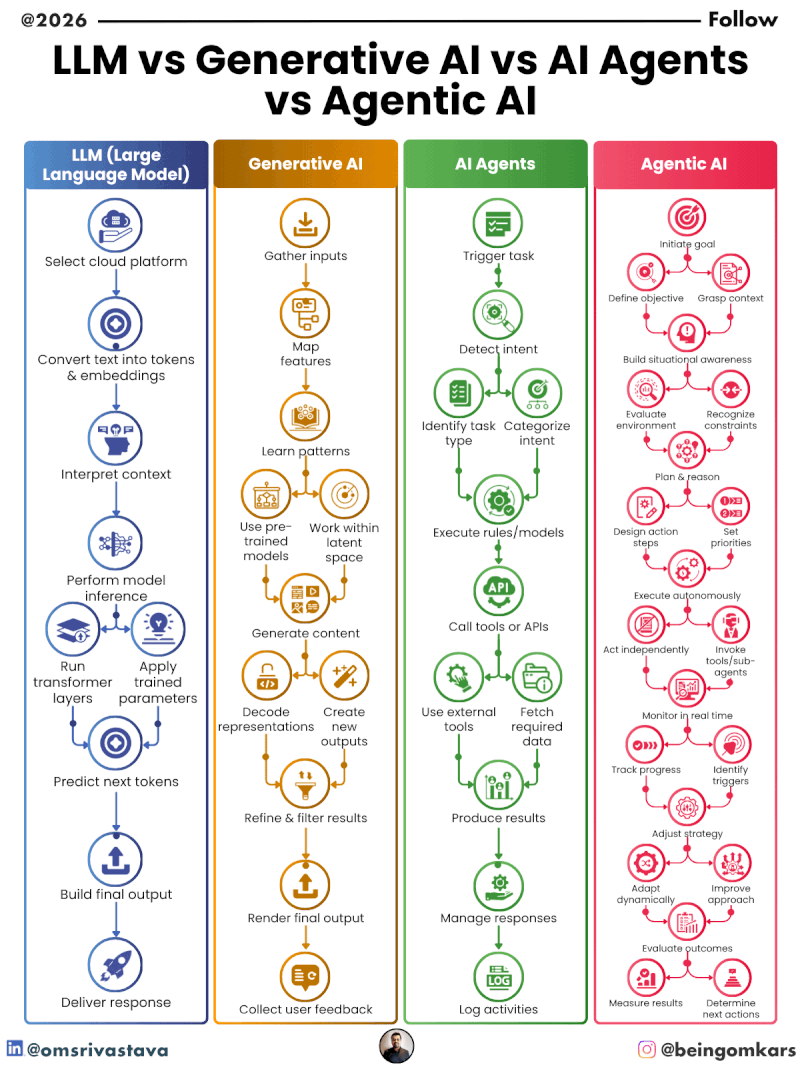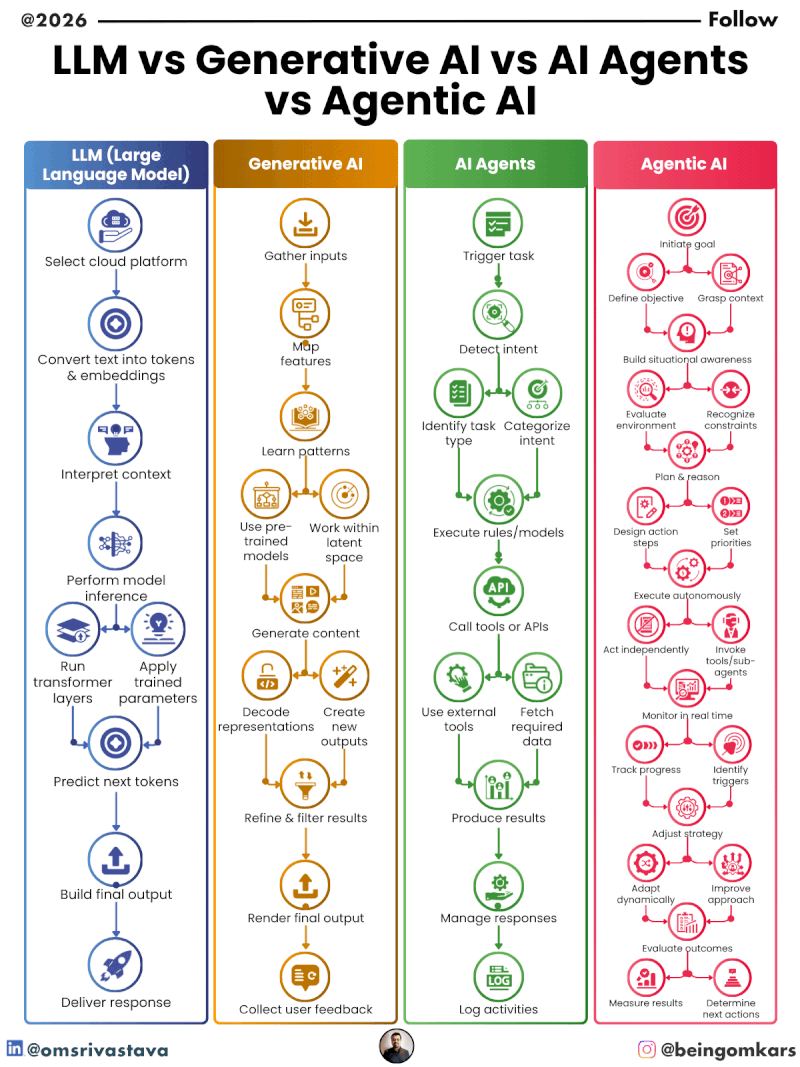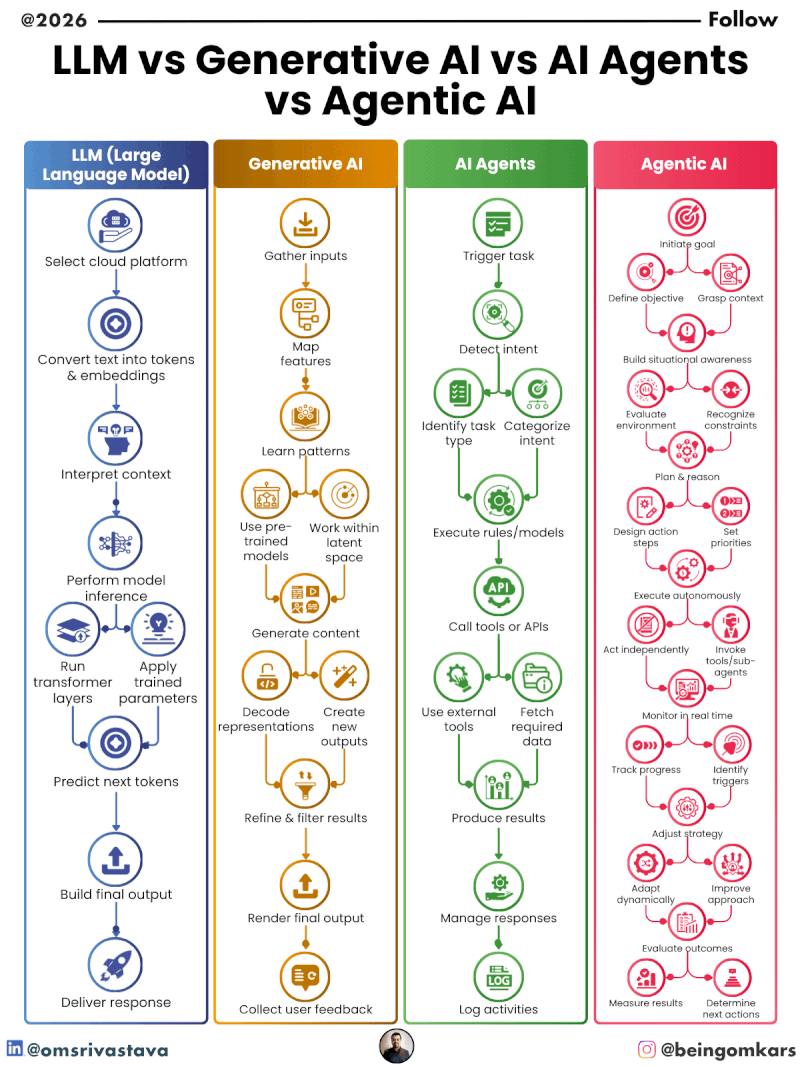
The cleanest way to think about this is in layers. At the bottom, you have raw statistical machinery — language models. Above that, you have the broader category of systems that generate content — generative AI. Above that, you have systems that can act — AI agents. And at the top (at least for now), you have systems that act autonomously, with judgment, over time — agentic AI.
Each layer builds on the one below. An LLM can exist without being wrapped in a generative AI product. A generative AI product doesn’t have to use agents. And AI agents aren’t automatically “agentic” in the full sense. The terms overlap, but they’re not the same thing, and the distinctions matter more the further up the stack you go.
LLMs: The Engine, Not the Car
A large language model is a statistical model trained on massive amounts of text. It learns patterns — which words follow which other words, across billions of examples — until it can generate plausible continuations of any given input. That’s it. That’s what it is at its core.
GPT-4, Claude, Gemini, Llama — these are LLMs. They take text in and produce text out. They do not browse the web (unless given a tool to do so). They do not remember your last conversation (unless explicitly given that memory). They do not decide to do things on their own. They respond to prompts.
What makes modern LLMs impressive isn’t just size, though scale matters. It’s the training process — specifically, reinforcement learning from human feedback — that shapes a raw text predictor into something that can reason, write code, summarize legal documents, explain photosynthesis to a ten-year-old, and translate Mandarin into French. The underlying mechanism is still “predict the next token,” but the emergent behavior is sophisticated enough that calling it “just autocomplete” is technically accurate and practically misleading.
One thing people consistently misunderstand: LLMs don’t know things the way you know things. They compress statistical relationships from training data into weights. When an LLM tells you something confidently wrong, it’s not lying — it’s doing exactly what it was built to do (predict likely text) and that prediction happened to be incorrect. This distinction matters when you’re deciding whether to trust the output.
Generative AI: The Product Layer
Generative AI is a broader category. It refers to any AI system whose primary output is new content — text, images, audio, video, code, 3D models, whatever. LLMs are one type of generative AI. DALL-E and Midjourney (image generation) are another. Sora and Runway (video) are another. Music generators like Suno are another.
What unites them: they don’t retrieve or sort existing content — they create novel outputs from learned patterns.
The term “generative AI” became dominant around 2022-2023, mostly because ChatGPT made text generation mainstream enough that people needed a word for it. Before that, the field used more specific terms: “language models,” “diffusion models,” “GANs.” Generative AI as a phrase is partly a marketing term. That doesn’t make it wrong — it’s a useful shorthand for a real category — but it explains why the definition feels slippery. It was always meant to be a big tent.
One thing generative AI is not: all AI. Recommendation systems, fraud detection, image classifiers, predictive maintenance tools — these are AI systems that don’t generate content. They predict, classify, or detect. Calling them “generative AI” is wrong, even if they’re impressively capable.
The practical upshot: when someone says “we’re using generative AI,” the useful follow-up question is which kind. LLM-based? Multimodal? Are they fine-tuning it? Running inference via API? The category is real but it doesn’t tell you much on its own.
AI Agents: When the Model Gets Tools
Here’s where the architecture gets more interesting.
An AI agent is a system where a language model (usually) is given tools it can use and is asked to complete a task, not just answer a question. The tools might include: searching the web, writing and executing code, reading files, calling APIs, sending emails, filling out forms. The model reasons about which tool to use, uses it, observes the result, and decides what to do next.
The defining characteristic of an agent isn’t intelligence — it’s action in the world. An agent doesn’t just generate text; it does things with consequences.
A simple example: you ask an AI assistant to book you a flight for next Tuesday. A bare LLM can tell you how to book a flight. An agent can actually do it — query flight APIs, compare options, enter your details, confirm the booking, send you a summary. The underlying language model is the same; what’s different is the scaffolding around it.
This matters more than it sounds. Once a system can take actions, you have to think about failure modes differently. A hallucination in a text response is annoying. A hallucination in an agent that’s managing your calendar or executing trades is a different category of problem. Agents require more careful design around error handling, confirmation steps, and scope limits.
The current generation of AI agents is mostly “tool-using LLMs in a loop.” The model generates a plan, executes one step using a tool, observes the result, generates the next step. Frameworks like LangChain, AutoGen, and similar libraries are largely infrastructure for managing this loop — keeping track of state, passing results back to the model, handling errors.
Most real-world agents today are fairly narrow. They’re good at well-defined tasks with clear success criteria: “summarize all emails from this sender,” “run this data pipeline and report anomalies,” “check these code changes for security issues.” They struggle with ambiguity, unexpected states, and tasks that require genuine judgment about tradeoffs.
Agentic AI: Autonomy Over Time
If AI agents are systems that can act, agentic AI is about how they act — specifically, with increasing autonomy, across extended timeframes, with minimal human intervention in the loop.
The word “agentic” describes a property, not a product category. A system is “more agentic” the more it can: plan multi-step tasks without being told each step, make decisions in novel situations, handle errors without human escalation, pursue goals over hours or days rather than single interactions, and coordinate with other agents.
This is where the field is heading, and it’s also where the hype is most disconnected from current reality.
The vision of agentic AI — a system you give a goal to on Monday that returns with results on Friday, having navigated obstacles, made reasonable tradeoffs, and done useful work without constant supervision — is real as a direction of travel. It is not, for most tasks, real as a current capability. Today’s agentic systems are impressive demos that fail in frustrating ways when deployed at scale on real-world complexity.
That said, some domains are working better than others. Agentic AI for software development (agents that can write tests, find bugs, generate pull requests, run CI pipelines) is genuinely useful today if you’re careful about the scope you give it. Same for research tasks where the agent is summarizing and synthesizing rather than making consequential decisions. The trick is keeping humans in the loop at the right checkpoints.
The reason “agentic” is the right word for this layer is that it captures the key shift: the system isn’t just responding to instructions — it’s pursuing goals. That’s a meaningful difference in how you have to think about oversight, accountability, and trust.
The Differences That Actually Matter
Put it together:
An LLM is a model. It takes input, produces output. No memory, no tools, no actions unless you add them.
Generative AI is a category of AI that creates new content. LLMs are a subset. The category includes image, video, and audio generators.
An AI agent is a system built around a model that can use tools and take actions. The model is usually an LLM. The agent is the whole system: model + tools + loop + state management.
Agentic AI describes agents that operate with greater autonomy, over longer time horizons, with less human intervention. It’s the high end of agent design — and the direction the field is pushing toward.
The practical confusion usually comes from collapsing these distinctions. When a company says “we’re building with AI,” they probably mean they’re calling an LLM API. When they say “we’re building AI agents,” they might mean anything from “we have a chatbot with a web search tool” to “we have multi-agent pipelines running autonomously in production.” When they say “agentic AI,” they might mean the latter — or they might be using the term because it sounds impressive.
Why the Distinctions Matter in Practice
If you’re building something:
A bare LLM API is right when you need text generation, classification, or summarization with a human reviewing the output. Cheap to run, fast to build, easy to debug.
An agent architecture makes sense when the task requires taking actions or using multiple data sources. Worth the added complexity only if a human-in-the-loop approach is too slow or too costly.
Full agentic design — long-horizon autonomous operation — should be reserved for tasks where the cost of human supervision exceeds the cost of occasional agent failure. That’s a high bar. Most teams aren’t there yet.
If you’re evaluating vendors: the LLM vs generative AI vs agent distinction is a good filter for marketing noise. A “generative AI platform” might just be an LLM wrapper. An “agentic solution” might be a chatbot with one search tool. Ask specifically: what does the system actually do? What can it act on? What requires human approval? How does it handle errors?
The Honest State of Things
LLMs are mature technology. Not perfect — hallucinations are real, context windows have limits, costs are non-trivial — but deployed at production scale across thousands of applications. This part of the stack works.
Generative AI broadly is mature for text and code, increasingly reliable for images, still inconsistent for video and audio.
AI agents work well in narrow domains with good tooling and human oversight. They break in unpredictable ways in open-ended tasks.
Agentic AI is real as a research direction and early deployment category. It is not mature. The gap between demo and production is wide. The companies claiming otherwise are mostly selling futures.
Understanding these layers doesn’t require a PhD in machine learning. It just requires being willing to ask the boring question — “but what does it actually do?” — before assuming the terminology means what you want it to mean.