Have you ever wondered what happens behind the scenes when you type a question into ChatGPT and receive a detailed, human-like response in seconds? It’s not magic—it’s advanced artificial intelligence powered by deep learning, vast datasets, and sophisticated algorithms. But how does it actually work? What makes ChatGPT capable of understanding context, generating coherent text, and even mimicking conversational tone?
This article breaks down the inner workings of ChatGPT in a clear, factual, and accessible way. We’ll explore the technology behind it, the training process, how it generates responses, and the limitations it still faces. Whether you’re a student, a professional, or simply curious about AI, this guide will give you a solid understanding of how ChatGPT operates—without the hype or technical jargon overload.
What Is ChatGPT?
ChatGPT is a large language model (LLM) developed by OpenAI. It belongs to a class of AI systems designed to understand and generate human-like text based on the input it receives. Unlike traditional software that follows strict rules, ChatGPT learns patterns from massive amounts of text data and uses that knowledge to predict what words should come next in a given context.
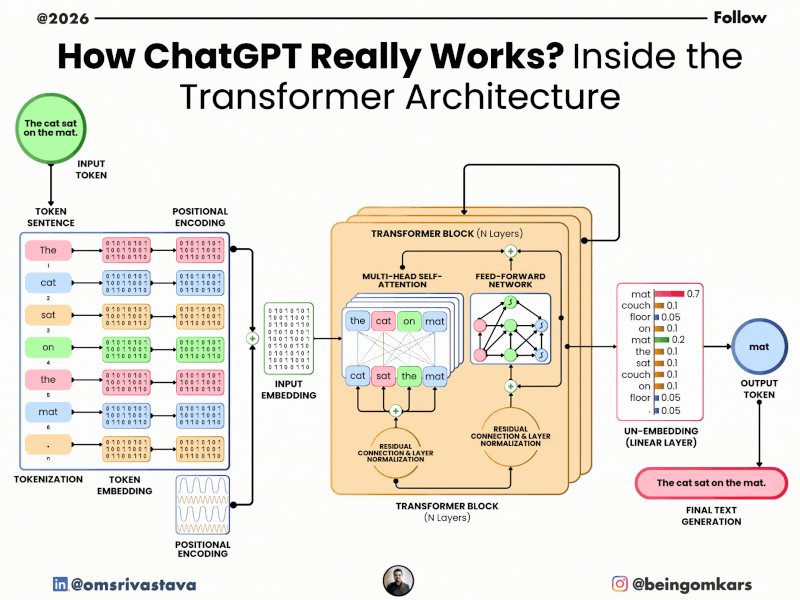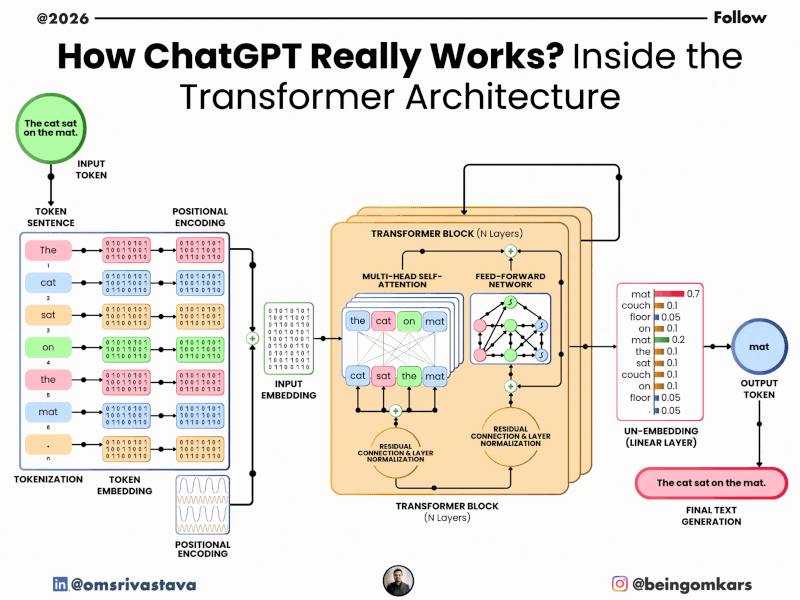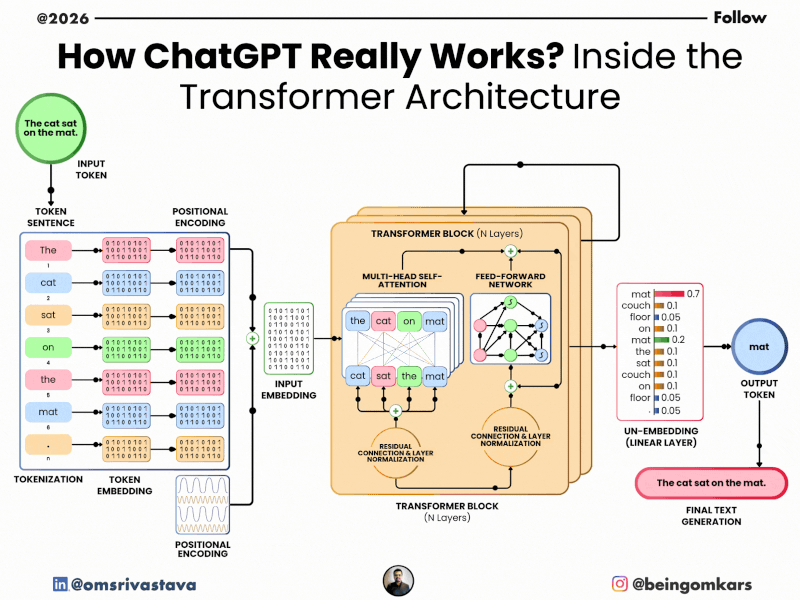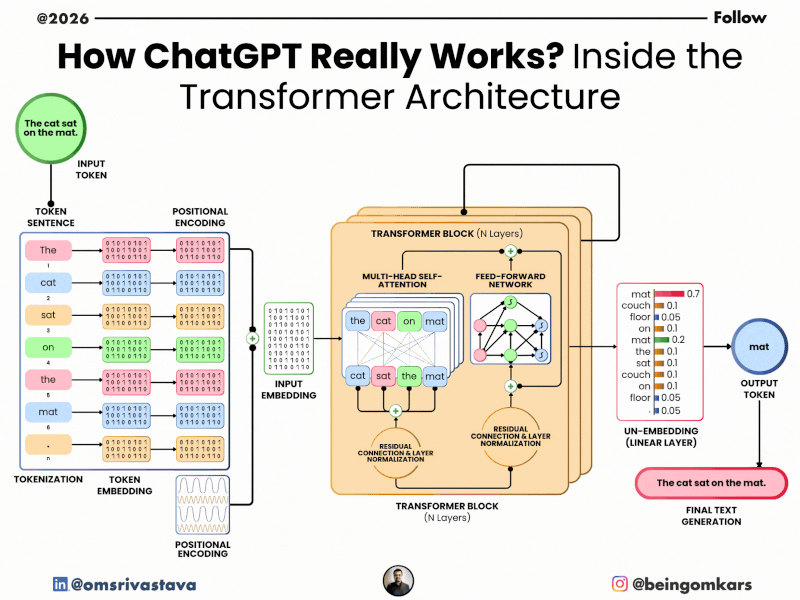
At its core, ChatGPT is built on a neural network architecture called the Transformer, which was introduced in a 2017 research paper titled “Attention Is All You Need.” This architecture allows the model to process words in relation to each other, capturing context and meaning more effectively than earlier models.
ChatGPT is not a search engine. It doesn’t “look up” answers in real time. Instead, it generates responses based on patterns it learned during training. This means its knowledge is static—up to a certain cutoff date—and it doesn’t have access to live data unless connected to external tools.
The Foundation: Large Language Models
To understand how ChatGPT works, it’s important to first grasp the concept of large language models. These are AI systems trained on enormous datasets of text from books, websites, articles, and other sources. The “large” in LLM refers to both the size of the training data and the number of parameters—internal settings that the model adjusts during training to improve its predictions.
For example, GPT-3, the predecessor to ChatGPT, had 175 billion parameters. GPT-4, which powers the more advanced version of ChatGPT, is even larger, though OpenAI has not disclosed the exact number. More parameters generally mean better performance, but also greater computational demands.
These models don’t “understand” language the way humans do. Instead, they learn statistical relationships between words. If the word “cat” often appears near “meow” or “whiskers” in training data, the model learns to associate them. Over time, it builds a complex map of word usage, grammar, and context.
How Was ChatGPT Trained?
Training ChatGPT involves two main phases: pre-training and fine-tuning.
Phase 1: Pre-training
In the pre-training phase, the model is exposed to a vast corpus of text—often hundreds of billions of words—from sources like books, Wikipedia, news articles, and websites. During this phase, the model learns to predict the next word in a sentence.
For example, if the input is “The sky is…”, the model might predict “blue” as the most likely next word. This process is repeated millions of times across diverse texts, allowing the model to learn grammar, facts, reasoning patterns, and even some forms of common sense.
This phase requires enormous computational resources. Training GPT-3 reportedly used thousands of GPUs and took weeks to complete. The result is a general-purpose language model that can handle a wide range of tasks, from writing essays to answering questions.
Phase 2: Fine-tuning
After pre-training, the model undergoes fine-tuning to improve its performance and align it with human preferences. This is where ChatGPT becomes more conversational and useful in real-world applications.
Fine-tuning typically involves two steps:
- Supervised Fine-Tuning (SFT): Human trainers provide example conversations where they demonstrate how the model should respond. For instance, a trainer might write a dialogue where a user asks for help with homework, and the model provides a helpful, polite, and accurate answer. The model learns from these examples to mimic the desired behavior.
- Reinforcement Learning from Human Feedback (RLHF): In this step, human evaluators rank different responses generated by the model. The model then uses reinforcement learning to adjust its behavior, favoring responses that receive higher ratings. This helps the model become more aligned with human values—such as being helpful, truthful, and harmless.
RLHF is a key innovation that sets ChatGPT apart from earlier models. It allows the AI to learn not just what to say, but how to say it in a way that feels natural and appropriate.
How Does ChatGPT Generate Responses?
When you type a prompt into ChatGPT, the model doesn’t “think” in the human sense. Instead, it processes your input through its neural network and generates a response word by word, using probability.
Here’s a simplified breakdown of the process:
- Tokenization: Your input text is broken down into smaller units called tokens. These can be words, parts of words, or even punctuation. For example, the sentence “Hello, how are you?” might be split into tokens like [“Hello”, “,”, “how”, “are”, “you”, “?”].
- Encoding: Each token is converted into a numerical representation (a vector) that the model can process. These vectors capture semantic and syntactic information.
- Context Processing: The model uses its Transformer architecture to analyze the relationships between tokens. It pays attention to which words are most relevant to predicting the next word, based on patterns learned during training.
- Prediction: The model predicts the most probable next token. It doesn’t choose just one—it considers multiple possibilities, each with a probability score. The final choice may be influenced by settings like “temperature,” which controls randomness.
- Decoding: The selected token is converted back into text and added to the output. The process repeats until the response is complete or reaches a length limit.
This word-by-word generation allows ChatGPT to produce fluent, contextually appropriate text. However, because it relies on probability, it can sometimes produce incorrect or nonsensical answers—especially when dealing with ambiguous or poorly defined prompts.
Understanding Context and Memory
One of ChatGPT’s strengths is its ability to maintain context within a conversation. For example, if you ask, “What is photosynthesis?” and then follow up with “How does it benefit plants?”, the model understands that the second question relates to the first.
This contextual awareness comes from the Transformer’s attention mechanism. The model assigns different levels of importance (attention weights) to different parts of the input. Earlier messages in the conversation are given less weight over time, but they still influence the response.
However, ChatGPT has a limited “memory” or context window. This is the maximum amount of text it can consider at once—typically around 4,000 to 32,000 tokens, depending on the version. Once this limit is reached, older parts of the conversation are forgotten. This is why long conversations may lose coherence over time.
It’s also important to note that ChatGPT does not have persistent memory across sessions. Each conversation starts fresh unless you’re using a platform that saves chat history. The model doesn’t “remember” past interactions unless they’re included in the current prompt.
What Can ChatGPT Do?
ChatGPT is versatile and can perform a wide range of language-based tasks. Some of its common applications include:
- Answering Questions: It can provide explanations on topics ranging from science to history, though accuracy depends on the quality of its training data.
- Writing and Editing: It can draft emails, essays, stories, and even code. It can also help revise and improve existing text.
- Translation: While not perfect, it can translate between many languages, often with reasonable fluency.
- Summarization: It can condense long articles or documents into shorter summaries.
- Programming Help: It can generate, debug, and explain code in various programming languages.
- Creative Tasks: It can write poetry, compose music lyrics, or brainstorm ideas for projects.
These capabilities stem from the model’s broad training and its ability to generalize from patterns in data. However, performance varies by task and domain. For example, it may excel at creative writing but struggle with highly technical or niche subjects.
Limitations and Challenges
Despite its impressive abilities, ChatGPT is not perfect. It has several well-documented limitations:
Factual Accuracy
ChatGPT can generate plausible-sounding but incorrect information. This is because it predicts text based on patterns, not verified facts. It may confidently state falsehoods, especially on topics not well-represented in its training data.
For example, it might invent historical dates, misattribute quotes, or provide outdated scientific information. Users should always verify critical information from reliable sources.
Hallucinations
A “hallucination” occurs when the model generates information that is not grounded in reality or its training data. This can include fictional events, non-existent sources, or made-up statistics. Hallucinations are more likely when the model is asked to speculate or generate creative content.
Bias and Fairness
Because ChatGPT is trained on data from the internet, it can inherit biases present in that data. These may include gender, racial, or cultural biases. OpenAI has implemented safeguards to reduce harmful outputs, but biases can still emerge, especially in sensitive contexts.
Lack of Real-Time Knowledge
ChatGPT’s knowledge is frozen at the time of its last training update. For example, if its cutoff date is September 2021, it won’t know about events that occurred after that. It cannot access current news, weather, or live data unless integrated with external tools.
Ethical and Safety Concerns
There are ongoing concerns about misuse, such as generating spam, misinformation, or harmful content. OpenAI has implemented content filters and usage policies to mitigate these risks, but no system is foolproof.
How Is ChatGPT Different from Other AI Tools?
ChatGPT is part of a broader ecosystem of AI language tools, but it stands out in several ways:
- Conversational Interface: Unlike search engines or databases, ChatGPT engages in dialogue, allowing follow-up questions and context-aware responses.
- Generative Capability: It doesn’t just retrieve information—it creates new text, making it useful for writing, brainstorming, and creative tasks.
- User-Friendly Design: Its interface is simple and accessible, requiring no technical knowledge to use.
- Continuous Improvement: OpenAI regularly updates the model based on user feedback and new research, improving performance over time.
Other AI tools, such as Google’s Bard or Meta’s Llama, operate on similar principles but may differ in training data, architecture, or intended use cases. Some are open-source, while others are proprietary.
Future Developments
The field of AI is evolving rapidly. Future versions of ChatGPT and similar models are expected to have:
- Improved reasoning and fact-checking abilities
- Larger context windows for longer conversations
- Better integration with real-time data and tools
- Enhanced safety and bias mitigation
- Multimodal capabilities (e.g., understanding images, audio, and video)
Researchers are also exploring ways to make models more efficient, reducing the computational cost and environmental impact of training and deployment.
Key Takeaways
- ChatGPT is a large language model trained on vast amounts of text data using deep learning.
- It works by predicting the next word in a sequence, based on patterns learned during training.
- Training involves pre-training on general text and fine-tuning with human feedback to improve alignment and safety.
- The model generates responses word by word, using a process called tokenization and decoding.
- It can maintain context within a conversation but has a limited memory window.
- ChatGPT is useful for writing, answering questions, translation, and more—but it is not infallible.
- Limitations include factual inaccuracies, hallucinations, biases, and lack of real-time knowledge.
- Ongoing research aims to improve accuracy, safety, and functionality in future versions.
FAQ
Can ChatGPT access the internet to get up-to-date information?
No, ChatGPT does not have direct access to the internet. Its knowledge is based on data available up to its training cutoff date. However, some versions of ChatGPT can use plugins or external tools to retrieve live information, but this is not part of the core model.
Does ChatGPT understand what it’s saying?
No, ChatGPT does not “understand” language in the human sense. It processes text statistically, predicting likely word sequences based on patterns in its training data. It lacks consciousness, intent, or genuine comprehension.
Is ChatGPT always accurate?
No, ChatGPT can make mistakes. It may provide incorrect facts, outdated information, or plausible-sounding but false answers. Users should verify important information from reliable sources and use the model as a tool, not an authority.