As artificial intelligence continues to evolve at an unprecedented pace, the way we interact with data and retrieve information is undergoing a fundamental transformation. One of the most significant advancements in this domain is the integration of Retrieval-Augmented Generation, commonly known as RAG, into modern AI systems. By 2026, RAG has become more than just a technical buzzword—it’s a foundational architecture shaping how intelligent applications access, interpret, and deliver knowledge. But what exactly are RAG design patterns, and why are they critical for developers, businesses, and researchers to understand?
This article explores the core principles of RAG, its architectural components, the various design patterns emerging in 2026, and their practical implications across industries. Whether you’re building a customer support chatbot, a medical diagnosis assistant, or a legal research tool, understanding RAG design patterns is essential for creating AI systems that are accurate, reliable, and contextually aware.
What Is RAG and Why Does It Matter?
RAG stands for Retrieval-Augmented Generation. It is a hybrid AI framework that combines the strengths of retrieval-based models and generative language models. In simpler terms, RAG systems don’t rely solely on the knowledge embedded during training. Instead, they dynamically retrieve relevant information from external databases or knowledge sources at the time of generating a response.
This approach addresses one of the most persistent challenges in generative AI: hallucination—the tendency of large language models (LLMs) to generate plausible but factually incorrect information. By grounding responses in real-time data, RAG significantly improves accuracy and trustworthiness.
The significance of RAG lies in its ability to bridge the gap between static knowledge (what the model learned during training) and dynamic, up-to-date information. For example, a financial advisory chatbot trained in 2023 wouldn’t know about a new tax regulation introduced in 2025. But a RAG-powered system can pull the latest policy documents and incorporate them into its responses.
The Core Components of a RAG System
A typical RAG architecture consists of three main stages: retrieval, augmentation, and generation. Each plays a distinct role in ensuring the final output is both relevant and accurate.
- Retrieval: When a user submits a query, the system searches a knowledge base—such as a document repository, database, or vector store—for relevant passages or documents. This is often done using embedding models that convert text into numerical vectors, enabling semantic similarity matching.
- Augmentation: The retrieved information is then combined with the original user query to form an enriched prompt. This augmented context provides the generative model with factual grounding.
- Generation: Finally, a language model (like GPT, Llama, or Mistral) uses the augmented prompt to generate a coherent, contextually appropriate response.
This modular design allows for flexibility and scalability. Developers can update the knowledge base without retraining the entire model, making RAG systems highly adaptable to changing information landscapes.
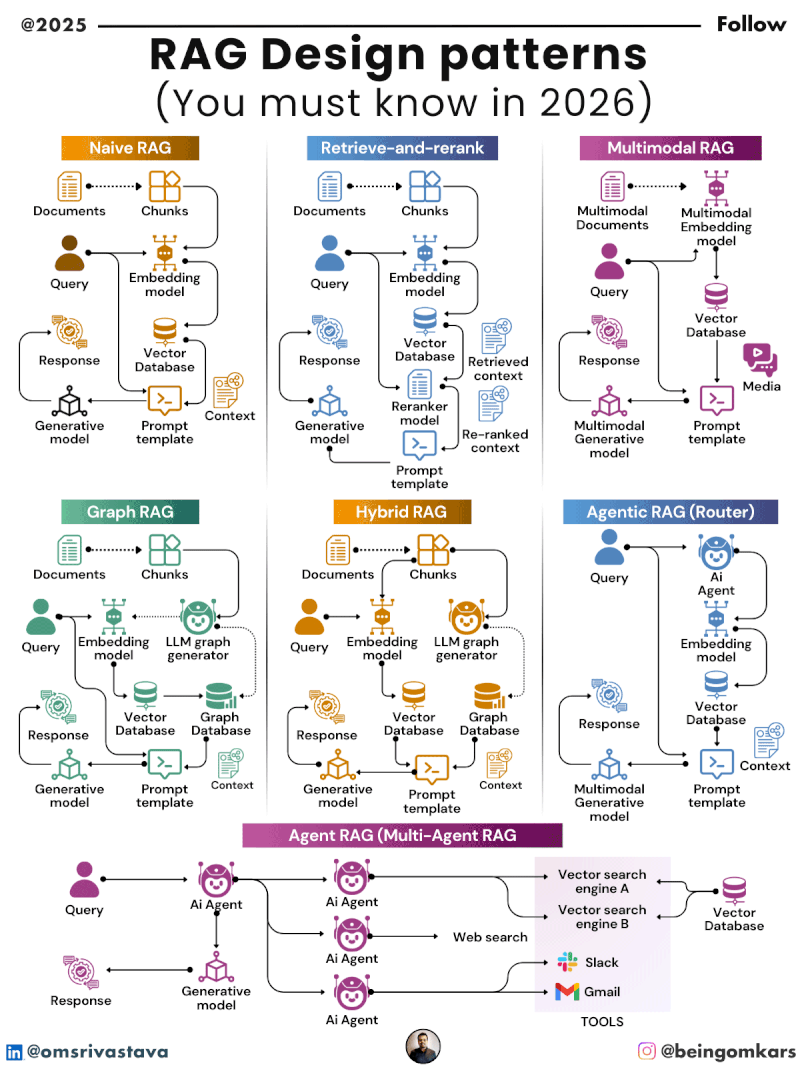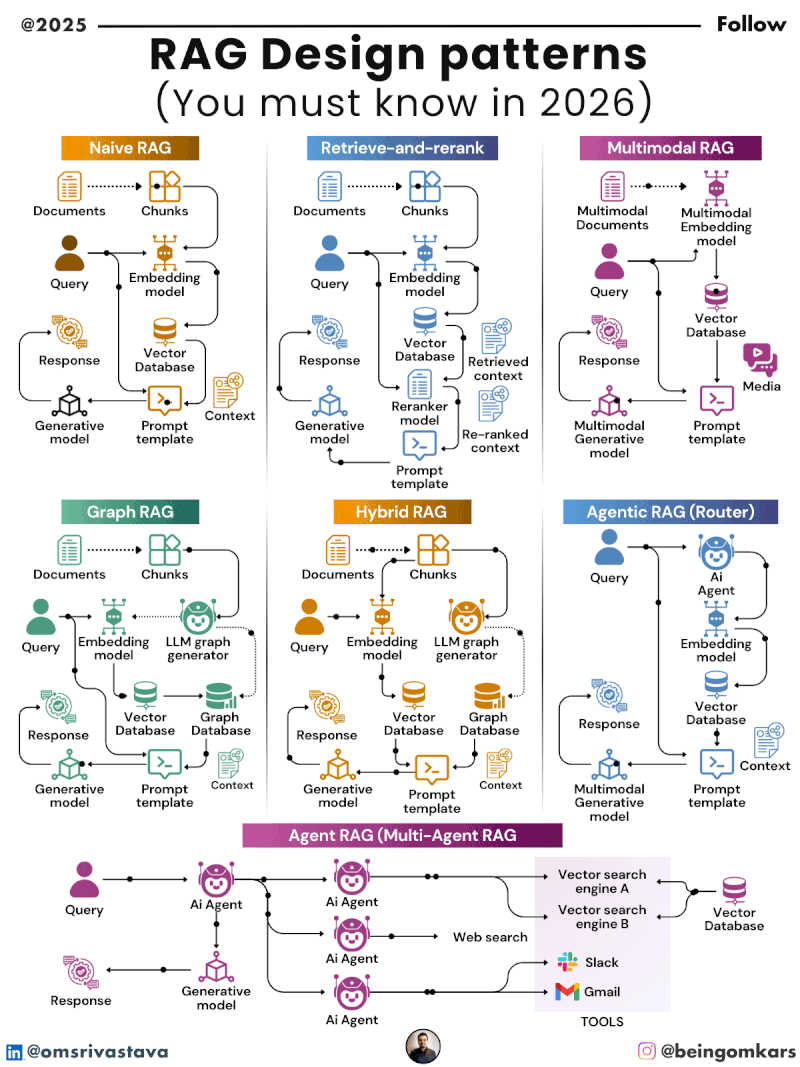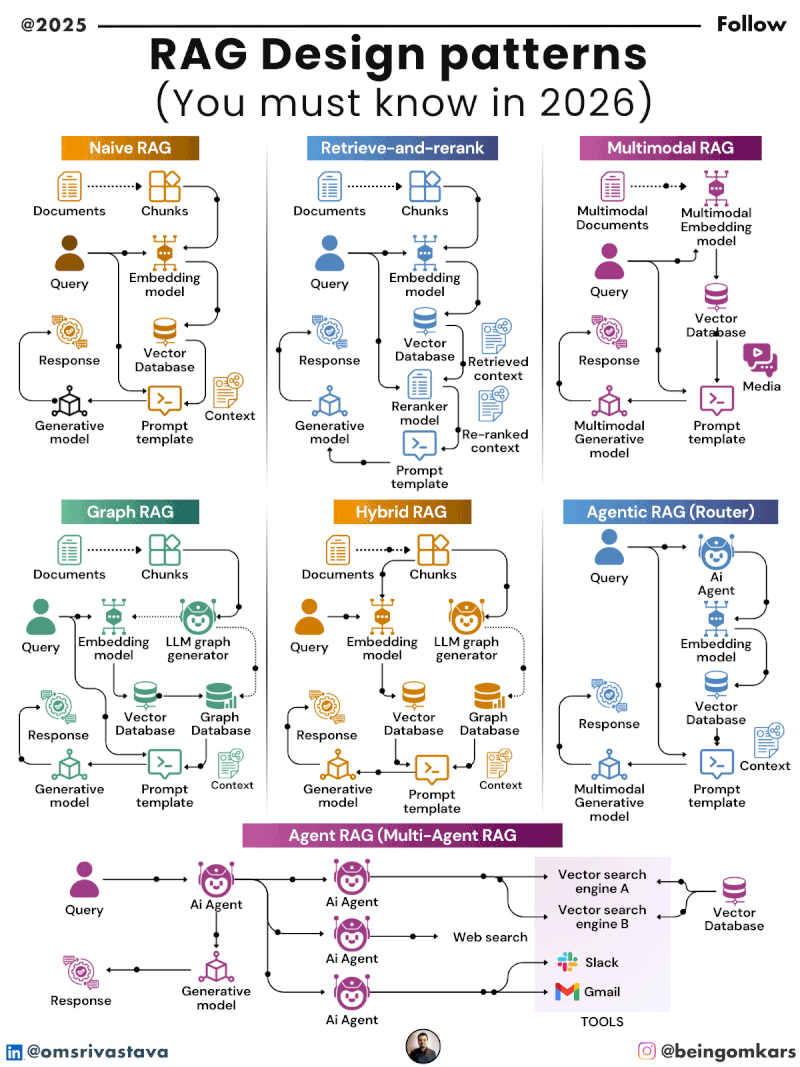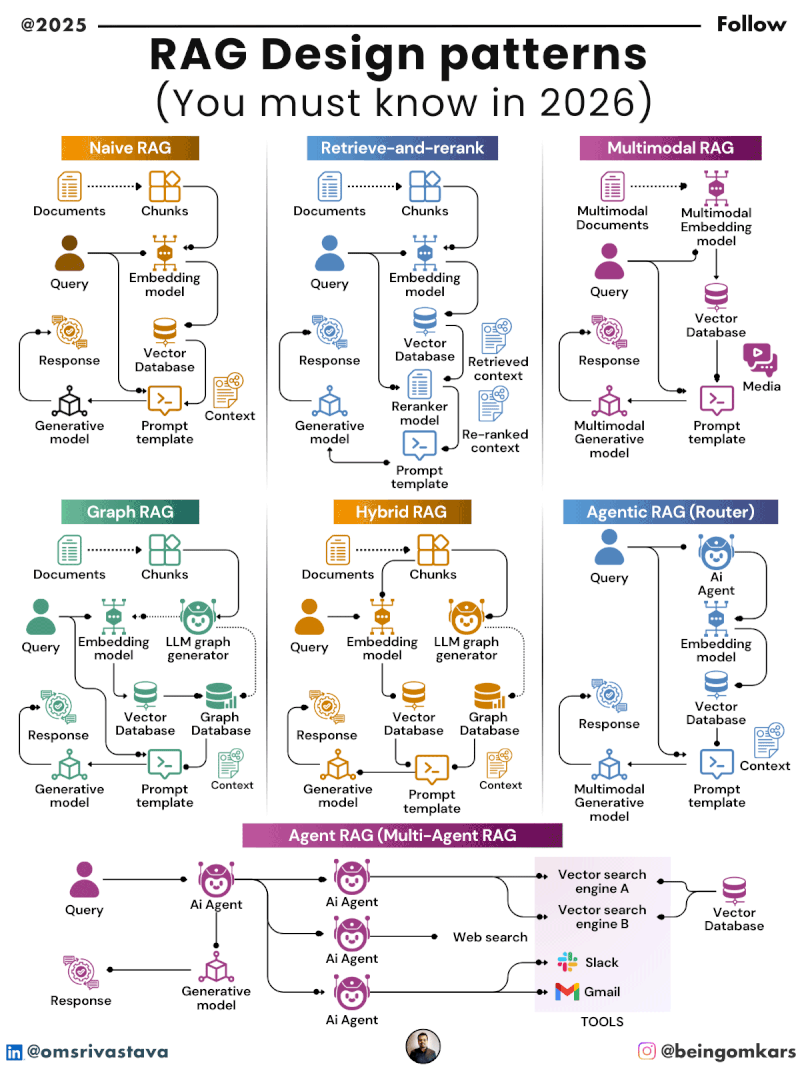
Key RAG Design Patterns in 2026
By 2026, several RAG design patterns have emerged as best practices, each tailored to specific use cases and performance requirements. These patterns reflect lessons learned from real-world deployments and ongoing research in retrieval efficiency, latency optimization, and knowledge freshness.
1. Naive RAG
The Naive RAG pattern is the simplest and most widely adopted form. It follows the basic three-step process: retrieve documents based on the query, augment the prompt with those documents, and generate a response.
While easy to implement, Naive RAG has limitations. It often retrieves too many irrelevant documents, leading to information overload. Additionally, it doesn’t prioritize the most relevant passages, which can dilute the quality of the final output.
Despite its simplicity, Naive RAG remains popular for prototyping and low-stakes applications where speed and ease of deployment outweigh the need for precision.
2. Advanced Retrieval with Re-ranking
To improve retrieval quality, many systems now incorporate a re-ranking step. After an initial broad search, a secondary model scores and reorders the retrieved documents based on relevance to the query.
This pattern uses techniques like cross-encoders, which compare the query and each document in detail, or learned re-rankers trained on domain-specific data. The result is a more focused set of top-k documents that significantly enhance response accuracy.
For example, in a legal research application, re-ranking ensures that the most authoritative case law or statute is prioritized over tangential references. This pattern is especially valuable in domains where precision is critical.
3. Hybrid Retrieval
Hybrid retrieval combines multiple search strategies to maximize coverage and relevance. It typically integrates keyword-based search (like BM25) with semantic search (using vector embeddings).
Keyword search excels at finding exact matches and handling structured queries, while semantic search captures meaning and context. By blending both, hybrid retrieval achieves better recall and precision, especially for ambiguous or complex queries.
In 2026, hybrid retrieval is commonly used in enterprise search engines, where users may search using both natural language and technical terms. It’s also effective in multilingual environments, where semantic understanding helps bridge language gaps.
4. Iterative RAG
Iterative RAG takes a step beyond single-pass retrieval by allowing the system to refine its search over multiple rounds. After generating an initial response, the model analyzes gaps or uncertainties and performs additional retrievals to gather more information.
This pattern is particularly useful for complex, multi-part questions. For instance, a user asking about the environmental impact of a new technology might receive an initial overview, followed by deeper dives into carbon emissions, resource usage, and regulatory compliance based on follow-up retrievals.
While iterative RAG improves depth and completeness, it increases latency and computational cost. As such, it’s typically reserved for high-value applications like scientific research or strategic decision support.
5. Self-RAG
Self-RAG is a more autonomous pattern where the generative model evaluates the relevance and reliability of retrieved information before incorporating it into the response. It uses internal mechanisms—such as confidence scoring or entailment checks—to decide whether to trust, modify, or discard retrieved content.
This pattern reduces the risk of propagating misinformation and enhances the model’s ability to handle conflicting sources. For example, if two retrieved documents present opposing views on a medical treatment, Self-RAG can flag the discrepancy and either present both perspectives or seek additional evidence.
Self-RAG represents a shift toward more intelligent, self-regulating AI systems. It’s gaining traction in healthcare, journalism, and policy analysis, where factual integrity is paramount.
6. Modular RAG
Modular RAG emphasizes flexibility by decoupling the retrieval and generation components. Instead of a fixed pipeline, the system allows different retrieval modules (e.g., vector databases, graph databases, APIs) to be plugged in based on the task.
This pattern supports domain-specific customization. A financial RAG system might integrate real-time market data feeds, while an educational platform could connect to curated textbook repositories. Modularity also facilitates updates and maintenance, as individual components can be upgraded independently.
In 2026, modular RAG is increasingly supported by open-source frameworks and cloud platforms, enabling organizations to build tailored solutions without reinventing the wheel.
Challenges and Considerations in RAG Implementation
While RAG offers substantial benefits, it is not without challenges. Understanding these limitations is crucial for effective deployment.
Latency and Performance
Retrieval introduces additional processing time, especially when searching large or distributed knowledge bases. In time-sensitive applications like customer service, even a few seconds of delay can degrade user experience.
To mitigate this, developers use caching strategies, precomputed embeddings, and optimized indexing. Some systems also employ approximate nearest neighbor (ANN) search to balance speed and accuracy.
Knowledge Freshness
RAG systems depend on the timeliness of their data sources. Outdated or stale information can lead to incorrect responses, particularly in fast-moving fields like technology or finance.
Automated data pipelines, change detection algorithms, and version control mechanisms help maintain knowledge freshness. Some organizations also implement scheduled re-indexing or real-time syncing with live databases.
Scalability
As the volume of data grows, so do the demands on storage, indexing, and retrieval infrastructure. Scaling RAG systems requires careful planning around database architecture, load balancing, and distributed computing.
Cloud-based vector databases and serverless computing models have made it easier to scale RAG applications, but cost management remains a concern, especially for high-traffic services.
Security and Privacy
Retrieving data from external sources raises security and privacy issues. Sensitive information, such as personal health records or proprietary business data, must be protected from unauthorized access or leakage.
Encryption, access controls, and data anonymization are standard practices. Additionally, some RAG systems use on-premise deployments or private cloud environments to ensure data remains within organizational boundaries.
Applications of RAG in 2026
RAG design patterns are being applied across a wide range of industries, each leveraging the technology to solve domain-specific problems.
Healthcare
In healthcare, RAG powers clinical decision support systems that retrieve the latest medical guidelines, drug interactions, and research studies. Doctors can query symptoms or treatment options and receive evidence-based recommendations grounded in current literature.
For example, a RAG-enabled assistant might help a physician determine the appropriate dosage of a new anticoagulant by pulling data from clinical trials and regulatory approvals published in the last six months.
Legal and Compliance
Legal professionals use RAG to navigate complex regulatory environments. Systems can retrieve relevant statutes, case law, and compliance requirements based on jurisdiction, industry, or specific legal questions.
This reduces the time spent on manual research and minimizes the risk of overlooking critical precedents. In 2026, many law firms have integrated RAG into their internal knowledge management platforms.
Education and Research
Educational institutions and research organizations use RAG to create intelligent tutoring systems and literature review tools. Students can ask questions about historical events, scientific theories, or mathematical concepts and receive detailed explanations supported by authoritative sources.
Researchers benefit from RAG’s ability to synthesize information across thousands of papers, helping them identify trends, gaps, and connections in their fields.
Customer Support
Customer service chatbots powered by RAG can access product manuals, FAQs, and support tickets to provide accurate, context-aware responses. Unlike traditional chatbots that rely on scripted answers, RAG-based systems adapt to new products and policies without manual updates.
This leads to higher customer satisfaction and reduced resolution times, especially for technical or complex inquiries.
Enterprise Knowledge Management
Large organizations use RAG to centralize and democratize access to internal knowledge. Employees can query internal wikis, project documentation, and meeting notes to find information quickly, improving productivity and collaboration.
RAG systems in this context often integrate with existing tools like Slack, Microsoft Teams, or Confluence, creating seamless workflows.
Future Trends in RAG Design
As we move further into 2026, several trends are shaping the evolution of RAG design patterns.
Integration with Knowledge Graphs
Knowledge graphs—structured representations of entities and their relationships—are being increasingly integrated into RAG systems. Unlike flat document retrieval, knowledge graphs enable reasoning over connections, such as “Which companies acquired startups in the AI sector last year?”
This allows for more sophisticated queries and richer contextual understanding, paving the way for AI systems that don’t just retrieve facts but infer insights.
Multimodal RAG
Traditional RAG focuses on text, but multimodal RAG extends retrieval to include images, audio, video, and structured data. For example, a medical RAG system might retrieve both a research paper and a related MRI scan to support diagnosis.
Advances in multimodal embeddings and cross-modal retrieval are making this possible, opening new possibilities in fields like radiology, education, and content creation.
Personalized RAG
Personalized RAG tailors responses based on user profiles, preferences, and past interactions. A learning platform might retrieve different content for a beginner versus an expert, or adjust explanations based on a user’s preferred language or learning style.
This pattern enhances user engagement and effectiveness, particularly in adaptive learning and recommendation systems.
Federated and Edge RAG
To address privacy and latency concerns, federated and edge-based RAG models are emerging. These systems perform retrieval and generation locally on user devices or within private networks, reducing reliance on centralized servers.
This is especially relevant for mobile applications, IoT devices, and environments with limited connectivity.
Key Takeaways
- RAG combines retrieval and generation to produce accurate, up-to-date responses by grounding AI outputs in external knowledge.
- Multiple design patterns exist, including Naive RAG, Advanced Retrieval with Re-ranking, Hybrid Retrieval, Iterative RAG, Self-RAG, and Modular RAG, each suited to different use cases.
- Challenges include latency, knowledge freshness, scalability, and security, but these can be mitigated with proper architecture and infrastructure.
- RAG is widely used in healthcare, legal, education, customer support, and enterprise knowledge management.
- Future trends include integration with knowledge graphs, multimodal retrieval, personalization, and edge deployment.
FAQ
What is the main advantage of using RAG over traditional language models?
The primary advantage of RAG is its ability to access and incorporate up-to-date, external information at inference time. Unlike traditional language models that rely solely on static training data, RAG reduces hallucinations and improves factual accuracy by grounding responses in real-world knowledge sources.
Can RAG be used with any language model?
Yes, RAG can be integrated with most modern generative language models, including open-source models like Llama and Mistral, as well as proprietary ones like GPT. The key requirement is that the model supports prompt augmentation—i.e., it can generate coherent text based on an extended input that includes retrieved context.
How do I choose the right RAG design pattern for my application?
The choice depends on your specific needs. For simple applications with low latency requirements, Naive RAG may suffice. For high-accuracy domains like healthcare or law, consider Advanced Retrieval with Re-ranking or Self-RAG. If your data spans multiple formats or sources, Hybrid or Modular RAG offers greater flexibility. Evaluate factors like query complexity, data volume, update frequency, and performance constraints when making your decision.